






前回の記事では、Windows環境におけるComfyUIの導入手順を解説した。

環境構築を終えて実際に使い始めると、次に直面するのが画像生成の速度やVRAM消費の課題である。特にAMD Radeon環境の場合、デフォルト設定のままではGPUのポテンシャルを十分に発揮できないケースが多い。
そこで今回は、Radeon環境におけるComfyUIの高速化・最適化の手法を紹介する。
MIOpenの有効化
生成速度が15%から20%向上する、最も手軽で効果的な設定である。
ComfyUIの起動用バッチファイル(.bat)に以下の環境変数を追記するだけで有効になる。
set COMFYUI_ENABLE_MIOPEN=1
set MIOPEN_FIND_MODE=FASTVAE_KL_MEM_RATIOの最適化
VAE処理時のVRAM使用予測量を調整し、VRAMからメインRAMへの無駄なデータ退避(スワップ)を防ぐことで時間ロスをなくす手法。
AMD環境での初期値は見積もりが過剰のため、1.0 ~ 2.0の間に調整すると良い。
comfy/sd.pyを開き、以下の部分を書き換える。
変更前
if model_management.is_amd():
VAE_KL_MEM_RATIO = 2.73
else:
VAE_KL_MEM_RATIO = 1.0変更後
if model_management.is_amd():
VAE_KL_MEM_RATIO = float(os.getenv("VAE_KL_MEM_RATIO", "2.73"))
else:
VAE_KL_MEM_RATIO = 1.0起動用バッチファイルに追記して値を指定する。(例として2.0に設定する場合)
set VAE_KL_MEM_RATIO=2.0VAEのPytorch Attention有効化
AMD環境では強制的に無効化されているVAE処理におけるPytorch Attentionを有効化する。これにより、VRAMを効率よく使えるようになり消費量が減るほか、生成速度の向上や、大きな画像生成時のVRAM溢れを防ぐ効果がある。
comfy/model_management.pyを開き、以下の部分を2行削除する。
変更前
def pytorch_attention_enabled_vae():
if is_amd():
return False # enabling pytorch attention on AMD currently causes crash when doing high res
return pytorch_attention_enabled()変更後
def pytorch_attention_enabled_vae():
return pytorch_attention_enabled()起動オプションの最適化
2026年6月現在は--use-pytorch-cross-attentionが十分高速で安定しているため、基本的にこれを指定する。
VRAMに余裕がある場合は--highvramを指定することで常にVRAM上にモデルが展開されるため高速化される。指定した場合は起動時のコンソールにSet vram state to: HIGH_VRAMと表示される。
--force-fp16や--fp16-vaeなどはVRAM使用量を減らせるが、使用するモデルによっては真っ黒な画像が生成されることもある。相性が悪い場合は外そう。
参考として、以下に筆者が使っている起動バッチファイルの全文を示す。
@echo off
set HIP_VISIBLE_DEVICES=0
set PYTHON="%~dp0/venv/Scripts/python.exe"
set VENV_DIR=./venv
set COMFYUI_ENABLE_MIOPEN=1
set MIOPEN_FIND_MODE=FAST
set VAE_KL_MEM_RATIO=2.0
set COMMANDLINE_ARGS=--use-pytorch-cross-attention --auto-launch --preview-method auto
%PYTHON% main.py %COMMANDLINE_ARGS%
pauseRadeon RX 9070 XT環境でのベンチマーク結果
今回行った高速化の結果を検証する。環境や条件を以下に示す。
| 項目 | スペック/バージョン |
|---|---|
| GPU | Radeon RX 9070 XT 16GB |
| CPU | Ryzen 9 7900X |
| RAM | DDR5 64GB |
| OS | Windows 11 24H2 |
| AMD Software | 26.1.1 |
| ComfyUI | 0.22.0 |
- バッチカウントで8回測定し、初回と最大値、最小値を除いた5回の平均値をとる。
- シード値は「1234567890」からインクリメント
- 以下の2つのモデルを比較
| モデル | モデル名 | 解像度 | サンプラー | ステップ | バッチサイズ |
|---|---|---|---|---|---|
| SD1.5 | v1-5-pruned-emaonly-fp16 | 512 x 512 | Euler | 20 | 8 |
| SDXL | juggernautXL_ragnarokBy | 1024 x 1024 | Euler | 30 | 1 |
今回の結果をグラフにまとめると以下のようになった。
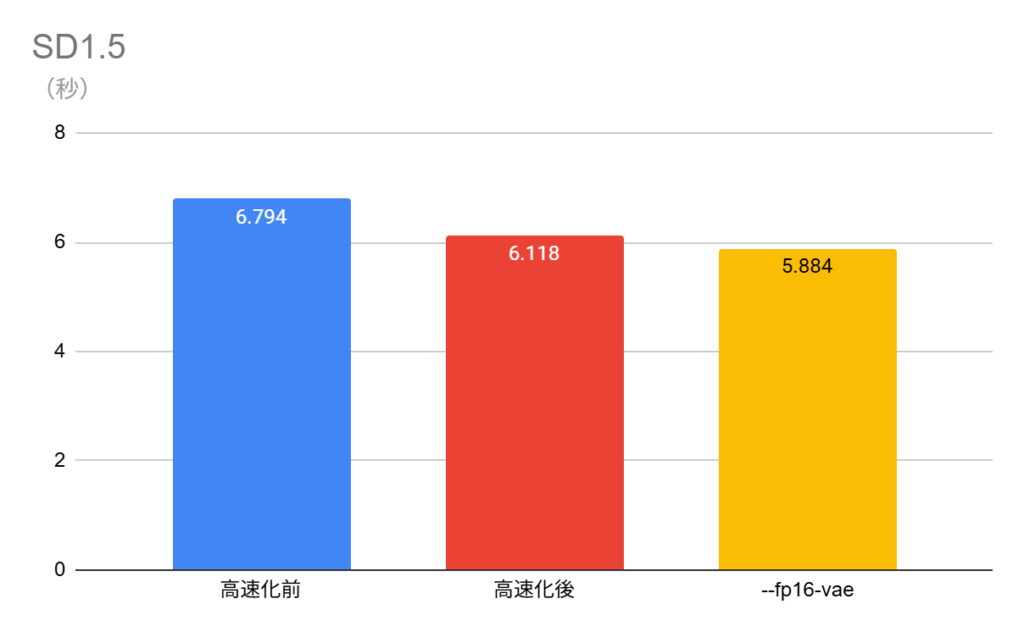
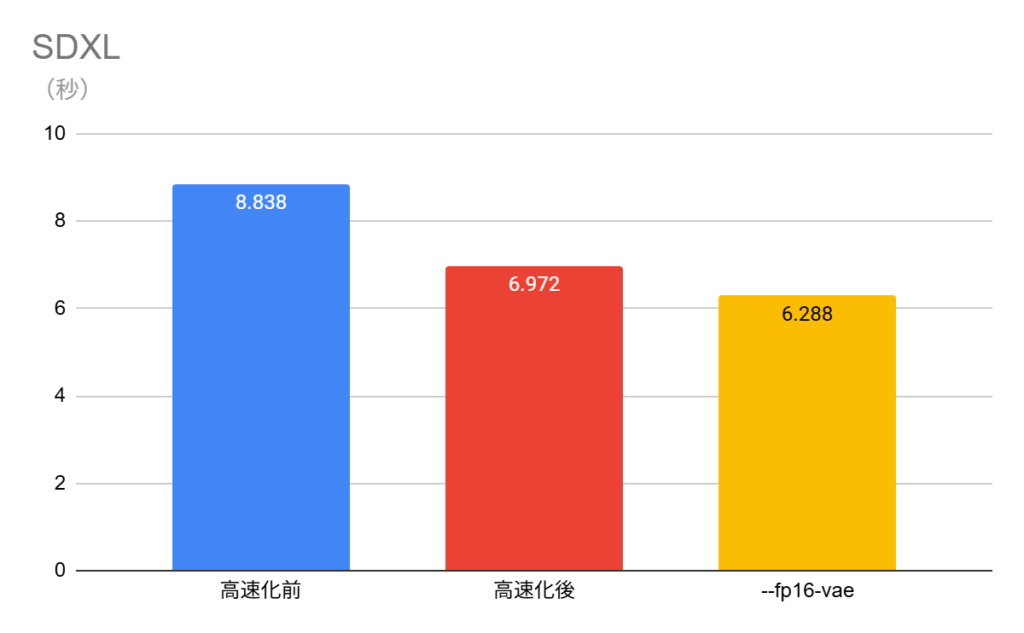
繰り返しになるが、--fp16-vaeは使用するモデルによって相性問題がある。今回の検証で使ったモデルでは有効だったが、それぞれの環境で使用の可否を確かめてほしい。
【最後に】設定で限界が来たら、ハードで解決する
ここまで紹介した4つはソフト側の最適化だが、突き詰めるとAI画像生成の快適さはメインメモリとVRAMで決まる。特にメモリ32GB環境でモデルの切り替えが遅い場合、64GBへの増設は設定いじりより体感効果が大きい。

PCごと新調するならBTOのサイコム、そもそもローカル構築をやめてブラウザで済ませたいならConoHa AI Canvasという手もある。


参考文献
今回参考にした記事は以下の通り。特に、1番目の記事では今回行った設定の背景も解説されている。



コメント